Agentic Analytics Platforms: 7 Criteria + 4 Picks (2026)
How to evaluate agentic analytics platforms. Seven criteria that separate real agent-native architecture from relabeled copilots, plus four recommendations.
In 2008, the USDA counted more than 400 eco-labels on food packaging in the United States. "Natural." "Farm-fresh." "Sustainably sourced." Most of them meant nothing. There was no standard definition, no enforcement, and of course, no consequence for slapping the word "organic" on a bag of chips that had never been in the same room as a farm. Shoppers who cared about what they were buying had to learn, on their own, which labels were regulated and which were theater.
That is the agentic analytics market right now.
Every BI vendor with a language model integration is repositioning as "agentic." The word has become a food label: applied liberally, defined loosely, and trusted only by those who skipped the fine print. The difference is that nobody got sick from buying the wrong olive oil. Choosing the wrong analytics platform because it called itself agentic can lock your data team into an architecture that looked modern in the demo and quickly abandoned by your actual users when it hit its ceiling by the second follow-up question.
So this guide provides seven criteria that distinguish platforms where agents can actually perform analytical work from platforms where "agentic" is a checkbox on a marketing page. The criteria are obviously opinionated, hence our recommendations are also biased.
7 Criteria That Actually Matter
Criterion 1: How expressive is the semantic layer?
The market has converged on a shared view: governed AI analytics should run through a semantic layer rather than brute-force text-to-SQL. That consensus is correct. But it hides a more important question.
How much of the real analytical question space can the semantic layer actually express?
There are three levels of AI analytics maturity. At level one, AI translates natural language directly into SQL against raw schemas. This is the purest form of text-to-SQL: fast to demo, fragile in production. The model infers business logic from column names and guesses join paths. Two users asking the same question get different answers.
At level two, AI maps requests into a structured intermediary format grounded in a conventional semantic layer: predefined metrics, dimensions, relationships. For simple questions ("monthly revenue by region for the last 12 months") this works well. The model's job is easier and answers are more consistent.
But this level has a hard ceiling, and it creates a problem called semantic leakage.
Once the question requires time comparisons, nested aggregation, ranking plus composition, cohort logic, cross-grain ratios, or parameterized metrics, the rigid intermediary format collapses. The system either rejects the question or falls back to generating SQL from scratch, which re-enters the text-to-SQL loop. When that happens, business logic that should live inside the governed semantic layer escapes into derived tables, dashboard formulas, or analyst workarounds. Metric definitions fork. Trust erodes. The architecture may still be marketed as "AI over semantic layer," but in practice it delivers conditional governance: governed when simple, probabilistic when hard.
At level three, the intermediary layer is an expressive query language purpose-built for analytics. AI still benefits from governed semantic definitions, but it can translate natural language into composable semantic queries that break the request into multi-step operations while staying inside governed business abstractions.
What to test: Ask the platform to answer a three-step question. Start with "show me revenue by region." Then: "compare that to the same quarter last year." Then: "show as a percentage of total, for enterprise accounts only, excluding churned customers."
Does the system stay inside governed definitions through all three steps? Or does it fall back to raw SQL at step two? If the agent generates raw SQL to handle a period comparison or a nested aggregation, the semantic layer sits at level two. Governance evaporates at the exact moment the analysis gets interesting.
A metric catalog (measures, dimensions, join paths, display names) falls short of what agents require. An agentic analytics platform needs composable analytical operations: period-over-period comparisons, cohort definitions, running totals, cross-grain ratios, and contribution analysis as first-class constructs in the semantic layer. The higher the metric expressiveness, the larger the governed surface area available to AI, and the less semantic leakage occurs.

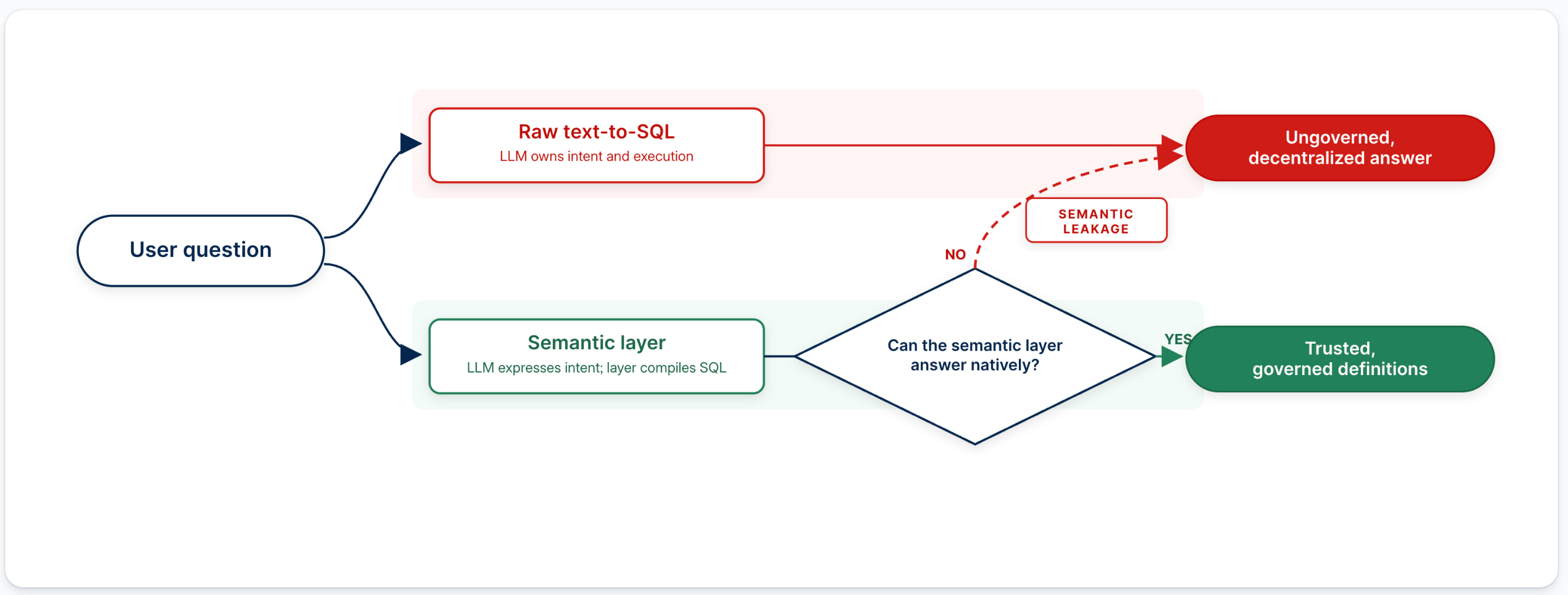
That is why "semantic layer present" is the wrong evaluation criterion. The right criterion is expressiveness. (For a deeper treatment, see the Holistics whitepaper "Why semantic layers differ".)
Criterion 2: What is the agent interface?
An agentic analytics platform exposes a machine-readable interface. A copilot exposes a chat box.
What to test: Can an external AI agent (Claude, a Slack bot, a Cursor workflow, a custom internal agent) connect to the platform and perform analytical work? Or is the only AI interface a text input inside the vendor's own UI?
What to look for: - CLI: for scripting, CI/CD, and command-line agent workflows - MCP server: the emerging standard for AI tool integration (Model Context Protocol) - SDK/API: for building custom agent experiences
If the only way to interact with the platform's AI is to type a question in the vendor's chat box, you are looking at a product with an AI feature, and the label "agentic" is decorative. True agentic analytics means agents from many surfaces (Slack, notebooks, IDEs, monitoring systems, internal apps) querying governed definitions. That requires machine-readable interfaces: CLI, MCP, API.
Criterion 3: Is the foundation code-first?
BI as Code is the architectural prerequisite for agentic analytics. AI agents work with code because code is what they can read, modify, test, and review.
What to test: How are metric definitions, data models, and business logic stored? In code files in a Git repository? Or as internal state inside the tool's database, configured through a GUI?
What to look for: - Version control. Are all analytics definitions tracked in Git? Can you see a diff of every metric change? Can you roll back? - Code review. Can metric definition changes go through pull requests before reaching production? - Testability. Can you write automated tests that validate metric correctness in CI/CD? - Agent readability. Can an AI agent parse the definition files and understand business logic without needing to interact with a GUI?
GUI-configured metrics are human-operable but machine-opaque. Code-defined metrics are both human-readable and machine-readable. In the agentic era, the second property is the one that matters more.
Criterion 4: How strong is the governance and trust layer?
When agents perform analytical work, the trust requirement is higher than when humans operate dashboards. A human building a wrong chart misleads one meeting. An agent producing a wrong analytical conclusion can mislead a decision chain.
What to test: Ask how you can trace from an agent's natural language answer back to the governed definition that produced it. Ask what happens when the agent encounters ambiguous business terms.
What to look for: - Lineage. Full traceability: natural language question → semantic resolution → compiled query → returned result. Each step inspectable. - Metric certification. Can metric definitions be certified by data teams, with uncertified definitions flagged? - Audit trail. Is every agent action logged: which definitions it used, which joins it traversed, which filters it applied? - Evals. Can you run automated evaluations that test agent output against known-correct answers for benchmark questions?
Governance in the agentic BI era is a structural requirement: the mechanism that converts "AI analytics" from a liability into a capability.
Criterion 5: How composable is the analytical language?
Business questions are compositional. "Revenue by region" is the first question. "Revenue by region, compared to last year, as a percentage of total, for enterprise accounts, excluding trial conversions before 2024" is the question that actually matters for a decision.
What to test: Can the platform's analytical language express these operations without falling back to raw SQL?
- Period-over-period comparison (this quarter vs last quarter)
- Nested aggregation (average of monthly sums)
- Cross-grain ratio (account-level metric divided by company-level total)
- Running totals and cumulative metrics
- Cohort-based filtering (customers who signed up in Q1 2025)
- Conditional metrics (revenue only from accounts with >$10K ARR)
What to look for: These should be first-class operations in the query language, built into the semantic layer itself. If the platform can define revenue but cannot compose revenue, this quarter, compared to last quarter, as percentage of total, for enterprise accounts inside the governed layer, then every complex question pushes the agent into ungoverned raw SQL.
Composability is the missing property in most semantic layers. It is the difference between a metric catalog and a meaning layer for agents.
Criterion 6: Does the platform build institutional memory?
Most AI analytics tools are stateless. Every conversation starts from zero. The agent has no way to know that "Q3 starts in February at our company" or that "the APAC region definition changed in March." It forgets everything between sessions. It stays static with use.
What to test: Ask what happens when the agent performs an analysis and discovers a useful metric definition missing from the semantic layer. Can that definition be promoted into the governed model?
What to look for: - Metric promotion loop. Agent-discovered definitions can be reviewed, refined, and certified by data teams, becoming permanent institutional knowledge. - Business context. The system retains organizational context: segment definitions, known data quality issues, pricing change dates, CRM data freshness caveats. - Reusable analytical playbooks. Common investigation patterns (revenue variance diagnosis, churn root-cause analysis, pipeline coverage check) can be defined once and reused across questions. - Learning from feedback. When a user corrects the agent, the correction compounds across future sessions.
A system that compounds knowledge with use is fundamentally different from one that generates one-off answers.
Criterion 7: Is the architecture infrastructure or feature?
This is the meta-criterion. It determines whether the platform can serve the full agentic analytics use case or is limited to one vendor's UI.
Infrastructure platforms expose the semantic layer as a runtime that multiple agents and surfaces can consume. A CLI, MCP server, SDK, and hosted control plane. The analytics definitions serve dashboards, Slack bots, notebooks, monitoring systems, and custom applications, well beyond the vendor's own UI.
Feature platforms add AI capabilities to an existing BI tool. The AI works only inside that tool. The semantic layer is accessible only through the vendor's interface.
| Infrastructure approach | Feature approach |
|---|---|
| Agent-neutral: any AI can connect | Vendor-locked: only the vendor's AI works |
| Multi-surface: dashboards, CLI, Slack, notebooks | Single-surface: the vendor's dashboard UI |
| Composable: MCP + CLI + SDK + hosted services | Monolithic: everything inside one app |
| Monetizes governance and control plane | Monetizes seats and dashboard engagement |
The infrastructure approach is harder to build but more durable. Its staying power comes from being the semantic layer that every agent uses, regardless of which chatbot UI is fashionable this quarter.
Evaluation framework
| Criterion | Question to ask vendors | Red flag |
|---|---|---|
| Semantic expressiveness | "Show me a three-step analytical question handled entirely in the governed layer" | Falls back to SQL at step 2 |
| Agent interface | "Can an external AI agent (outside your UI) connect and query?" | "We have a chat interface" |
| Code-first | "Where are metric definitions stored? Can I see a Git diff?" | "It's in the admin console" |
| Governance | "Show me the lineage from a natural language question to the SQL it ran" | Cannot trace |
| Composability | "Express a period-over-period comparison inside the semantic layer" | "You'd write that in SQL" |
| Institutional memory | "What happens to useful metrics the AI discovers?" | "Start a new conversation" |
| Architecture | "Can I connect from Slack / CLI / notebook without your UI?" | "All analytics go through our dashboard" |
4 Platforms Worth Evaluating
Applying the seven criteria above, four platforms stand out as genuinely pursuing the agentic analytics architecture, each with different strengths and trade-offs.
1. Holistics
What it is: A code-first agentic analytics platform built on AMQL, a semantic modeling language (AML) and composable query language (AQL) designed for both human and machine consumption.
Why it fits the criteria:
Holistics scores highest on the criterion that matters most: semantic expressiveness. AQL operates at level three of the maturity model described above. Natural language translates into AQL, a composable semantic query language where period comparisons, nested aggregations, cross-grain ratios, and cohort logic are first-class operations. AQL then compiles deterministically to SQL. The AI stays inside governed abstractions for the full question space, including the follow-up questions where conventional semantic layers hit the semantic ceiling and leak logic back into raw SQL.
A coding agent develops Holistics analytics from a prompt, with the real dashboard rendering live.
On the agent interface criterion, Holistics exposes an MCP server and CLI that any coding agent can connect to. Claude Code, Cursor, Codex, or a custom internal agent can explore models, run queries, inspect schemas, and build analytics through the same governed definitions. This means agents operate on the real semantic layer, grounded in metrics the team already trusts. The platform offers two development surfaces: a built-in Development Copilot (build datasets, dashboards, and descriptions in plain English, zero setup) and local agentic development (connect your own coding agent via MCP, edit AML in your IDE, preview live, ship through Git PRs and CI/CD).
Every model, metric, and dashboard is typed AML in Git. Changes go through pull requests. Validation runs in CI. The Publish API auto-deploys on merge. This is the same workflow data engineers already use for pipelines and transformations, extended to analytics.
Where it falls short: Smaller vendor than enterprise incumbents. Requires investment in building the semantic layer (though the code-first approach makes this more sustainable than GUI-configured alternatives). The category "agentic analytics infrastructure" is new, and buyers may need to evaluate it outside existing BI procurement frameworks.
Best for: Data teams that want AI agents to perform real analytical work through governed infrastructure, with the same code, Git, and CI/CD workflow they use for everything else.
2. Looker (+ Gemini)
What it is: Google's BI platform with a rich semantic layer (LookML) and Gemini AI integration.
Why it fits the criteria:
Looker's LookML is the most mature code-first semantic layer in the incumbent BI market. Definitions are version-controlled in Git. The modeling depth is strong: relationships, access filters, derived tables, and aggregate awareness are well-supported. Gemini integration adds natural language querying over the governed model.
Looker recently added an MCP server, opening agent connectivity beyond the Explore UI.
Where it falls short: LookML sits at level two of the maturity model. It is a rich metric and dimension catalog, but the query layer (Explore) maps to a metric-dimension-filter template. When questions require composable multi-step operations (period comparisons, nested aggregations, cross-grain ratios), the system either uses table calculations (which live outside the governed model) or requires derived tables (SQL workarounds maintained by analysts). LookML is also verbose, file-heavy for complex models, and requires specialist knowledge.
Best for: Organizations with existing LookML investment and Google Cloud infrastructure who want to add AI on a strong semantic foundation, and can accept the composability ceiling on complex follow-up questions.
3. Databricks (Genie + Unity Catalog)
What it is: A unified data platform with AI capabilities across the lakehouse, including Genie for natural language querying and Unity Catalog for governance.
Why it fits the criteria:
Databricks scores well on governance (Unity Catalog provides lineage, permissions, and data asset discovery) and on the infrastructure criterion (APIs and notebooks give agents programmatic access). The platform is strong for organizations where data engineering, ML, and analytics live on the same lakehouse.
Genie AI provides natural language querying, and Databricks' investment in the agent ecosystem (including its own agent framework) signals commitment to the agentic model.
Where it falls short: Databricks lacks a deep BI semantic layer. Unity Catalog governs data assets, but the metric definition layer is thin compared to AMQL or LookML. Follow-up questions that require composable metric operations still fall to SQL generation or notebook code. The BI/reporting surface (Lakeview) is less mature than dedicated BI tools. Pricing is usage-based and can be difficult to predict.
Best for: Data platform teams that already run engineering and ML on Databricks and want to extend AI to analytical querying within the same ecosystem, accepting that the BI-specific semantic layer is less expressive.
4. ThoughtSpot (Spotter)
What it is: A search-first analytics platform rebuilt around AI, with a proprietary semantic layer (Spotter Semantics) and conversational AI (Spotter).
Why it fits the criteria:
ThoughtSpot was built for natural language querying before the current AI wave, which gives it a head start on the interaction model. Spotter Semantics provides a governed layer that constrains AI to approved metrics and dimensions. Time-to-answer for first-order questions is fast, and the business user experience is strong.
Where it falls short: ThoughtSpot's semantic layer is proprietary and closed: definitions live inside the platform, with no Git-based version control, no CI/CD, and limited visibility into how metrics are defined. On the composability criterion, the intermediary format handles standard metric-dimension queries well but struggles with nested aggregation, cross-grain ratios, and multi-step analytical patterns. Follow-up questions can reset context. The agent interface is limited to the vendor's own UI, with no MCP server or external agent connectivity.
Best for: Organizations that prioritize time-to-value for business user self-service and can accept the composability ceiling on analytical depth.
How the four platforms compare on the seven criteria
| Criterion | Holistics | Looker + Gemini | Databricks | ThoughtSpot |
|---|---|---|---|---|
| Semantic expressiveness | Level 3: composable AQL | Level 2: rich LookML, rigid Explore | Level 1-2: thin metric layer, strong data catalog | Level 2: proprietary, standard depth |
| Agent interface | MCP server + CLI + API | MCP server + API | API + notebooks | Vendor UI only |
| Code-first | Full (AML in Git, CI/CD, PRs) | Full (LookML in Git) | Partial (notebooks, SQL) | None (GUI-configured) |
| Governance | Lineage, RLS, certification, evals | Lineage, access filters, LookML review | Unity Catalog, lineage, permissions | Role-based, limited audit trail |
| Composability | Period comparisons, nested aggs, cross-grain, cohorts as first-class | Table calculations + derived tables (outside governed model) | SQL/notebook (outside governed model) | Standard metric-dimension queries |
| Institutional memory | Metric promotion loop, context retention | LookML evolves through PRs | Notebooks persist, catalog evolves | Limited |
| Architecture | Infrastructure (multi-surface, agent-neutral) | Hybrid (strong modeling, GUI-bound query) | Infrastructure (platform-wide) | Feature (single-surface) |
The bottom line
The platform that wins the agentic analytics category will be the one that makes agents trustworthy: semantic infrastructure deep enough for real analytical work, composable enough for real business questions, and governed enough to be trusted at organizational scale. The most impressive chatbot demo is irrelevant if the semantic layer runs out of depth by the second question.
The chatbot is the interface. The semantic infrastructure is the product.
Ask the seven questions. The answers will tell you whether you are evaluating an agentic analytics platform or a dashboard tool with a new marketing page. (For a broader comparison of AI analytics platforms across 13 tools, see our full review.)

Data Engineer turned Product; writes SQL for a living.