The Two Philosophies of Cost in Data Analytics
There appears to be two philosophies today when it comes to managing costs in a modern data stack. We explore what they are.

Here are two stories, told back to back, and I’ll let you see if you can spot the fundamental difference in worldview between them.
A Fear of Query Costs
Story A was a prospective customer who was tasked with building a data team from the ground up. This was an incredibly experienced practitioner, who had many successful stints as head of data before his current role. Before speaking to us, he had already had conversations with reps from Tableau, Power BI, Periscope Data, Looker, Snowflake, Google Cloud, and a few others. This person was nothing if not meticulous; we learnt a lot from talking to him.
About 10 minutes into our conversation, he told us his overall strategy: “My plan is to have our engineers do ETL into Snowflake. Snowflake will be our primary data warehouse. And then we’re going to model everything using the data vault methodology, with dbt. dbt’s great. From there, we’ll build out data cubes for our analysts to use.”
We were a little confused. “Holistics connects directly to Snowflake, and we let you model everything you need within the database itself. You don't need cubes. We’re like Periscope and Looker in this regard. Is there a particular reason you’re not running it this way?”
“Oh no.” he said, “Oh I see.” he continued. “You’re a push-down tool like Periscope and Looker. You sit on top of the data warehouse and run queries. Right. No, I don’t want that. Data warehouses like Snowflake and RedShift charge by use. This means that running analysis on top of such data warehouses will get very expensive very quickly. Such tools are great if you need real-time analytics. My company doesn’t. We just need to run the numbers once a day. It’s cheaper and more effective if we build cubes from Snowflake instead.”
(Note: such tools are not used for real-time analytics only; more on this in a bit).
The Joy of Hiring Less
Story B is about a customer of ours. This was a major company in the e-commerce space in South East Asia. Their head of data agreed to sit down with us for an hour or so; we do regular customer check-ins for feedback every couple of quarters and this was our second time with him.
“Something interesting for you guys,” he said, in the middle of our meeting. “We’re finding that we don’t have to hire as many data engineers as before. It’s a relief.”
“How do you mean?” one of us asked.
“It’s really difficult to hire good data engineers in South East Asia. We’re not entirely sure why. The good ones cost a lot and we find that the candidates we source are either too junior, or if they’re experienced, then we have difficulty holding on to them. So using Holistics has actually made our hiring situation easier, because we can just hire analysts and they can accomplish the same things, without engineering help.
“Using a tool like Holistics — or anything like it, really — has been helpful. You can just get someone with SQL knowledge to do the work.”
The Two Philosophies
There appear to be two philosophies around cost in business intelligence right now. The first is to say — rightly! — that cloud-oriented data warehouses can become prohibitively expensive. Services like BigQuery and Snowflake charge by storage used and by query execution time; we’ve had our fair share of customer questions and internal discussions about whether query usage was becoming a cost problem. This is a natural side effect of the pay-as-you-go cloud business model — and is not something we see going away anytime soon.
On the other hand, we live in an age of incredibly expensive software engineering labor. The all-in cost of hiring a team of data engineers can be in the hundreds of thousands. (This assumes an average of $10k per month per engineer, which is reasonable when you add in benefits and 401(k) contribution; the net result is that the numbers add up really quickly). So if you pick a tool that allows analysts to do what they used to rely on data engineers to do, you're effectively looking at savings of a few thousand dollars a month.
The math we've covered here explains why certain data leads have decided to focus on reducing cloud costs, and others have focused on reducing engineering costs. These are the two philosophies of cost optimization in today’s world of business intelligence. Of the two philosophies, it’s the latter that’s become rather interesting for us to observe, given our vantage point here in Holistics.
Take this Hacker News thread on data stacks, for instance. The HN community is filled with technical folks in all parts of the tech ecosystem, and this particular discussion is filled with comments like:
If you have a data team: Stitch / Segment -> BigQuery -> Dataform -> BigQuery -> Looker
I work with many companies helping them set up their data stack, and from what I've seen this is pretty much the optimal set up. These tools all require very little maintenance, are relatively cheap (compared to the man power required to set these things up from scratch internally), and scale well as companies grow and complexity increases.
If you don't have a data team: Segment -> Amplitude/Mixpanel
Stitch/Fivetran/Custom -> Snowflake -> dbt -> Periscope
And another one:
Stitch/Airflow/Other -> Snowflake -> dbt -> Snowflake -> Redash + Tableau
Everything goes through S3 because Snowflake storage is on it.
dbt is amazing, we began using it a month ago and it already transformed the way our data team work. It really is a value multiplier for everyone. Data engineers are happier because they don't need to write and maintain data transformations, analysts are happier because they can maintain their own SQL pipelines & the whole company is happier because we now have a great documentation tool to explore our data.
We also are big fans of Snowflake, make operating a data warehouse a breeze.
Then, we use a mix of Redash & Tableau for reporting.
To generalise a bit, these perspectives are heavily weighted towards tools that empower data analysts. Notice that the majority of tools enable analysts with basic SQL knowledge to perform and manage transformations within the data warehouse … roles that traditionally have been the domain of the data engineer. The implication here is that such teams prefer to reduce the amount of data engineering needed to deliver business intelligence to the company. Such stacks look something like this:
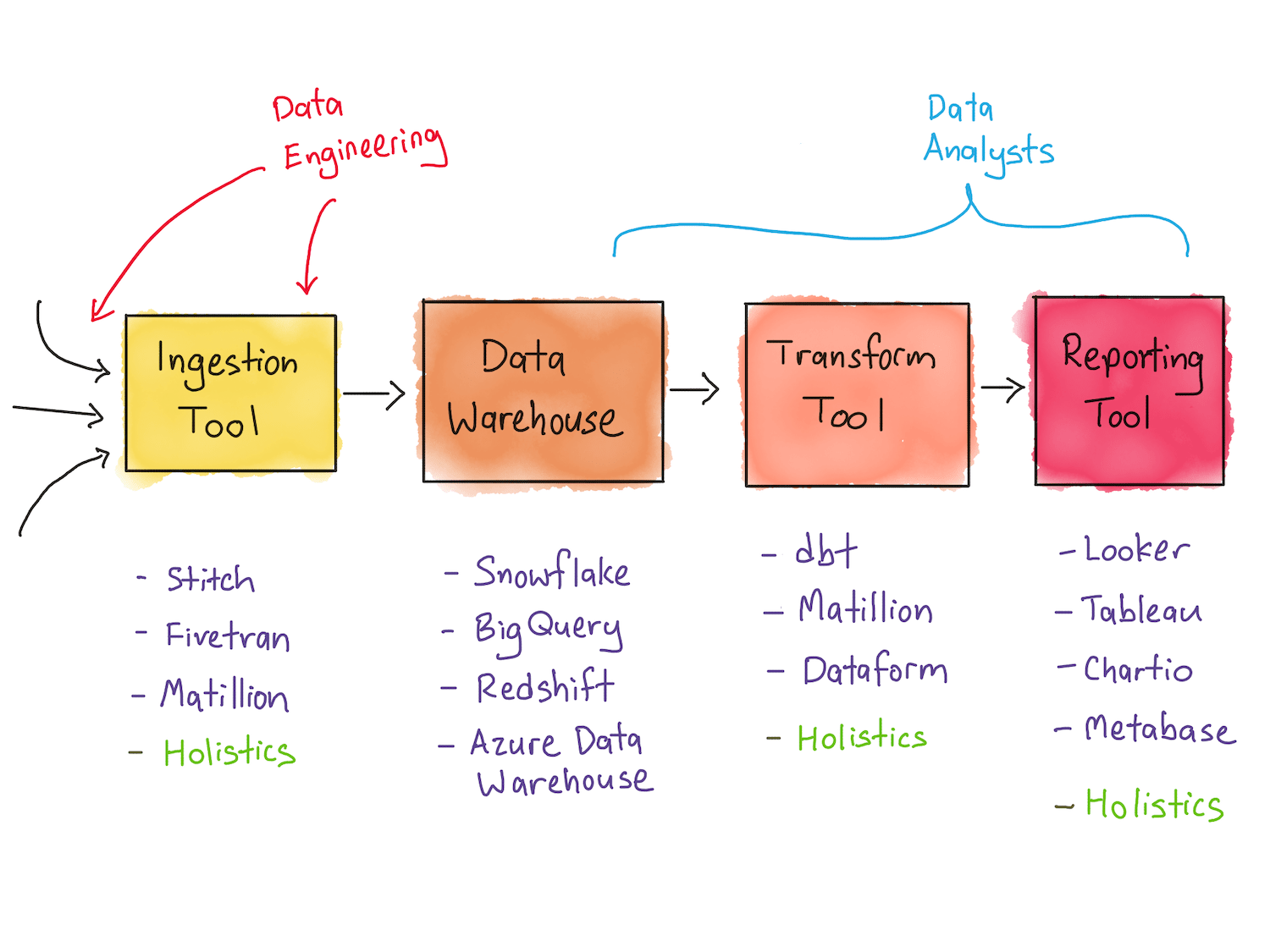 A modern data stack, optimized to reduce data engineering costs.
A modern data stack, optimized to reduce data engineering costs.
This matches the setup we’ve seen in our conversation with the data team lead in the second story, above.
On the other hand, companies who focus on running a cost-efficient data stack are perhaps willing to hire for such expertise, or have a good deal of in-house talent to begin with. Our first story presents an example of this, but look at this presentation by a data engineering manager at the OLX Group. They explain that given 100 million rows, a data cube solution like Apache Kylin is roughly 4.4x cheaper than running a similar level of analysis on cloud data warehouse Redshift.
We could go into the pros and cons of both kinds of stacks, but I’m going to skip that for the sake of brevity. What I think is clear from these examples is that both viewpoints are valid, and both viewpoints exist.
Don’t Listen To Us; Ask Around
Holistics is a cloud-based software provider, and we’ve built our company with the data analyst at heart. What we say on this topic shouldn’t be very convincing to you, because it’s clear where our biases lie.
That said, it is worth it, I think, to look around at the data teams you know and ping them to see if they belong to one worldview or the other. Work through their constraints: why have they chosen one approach vs the other? Could it be due to regulatory concerns? Or could it be that they’ve always done things a certain way?
The important thing is to recognise that two philosophies exist, and lie in tension with each other. Which philosophy you pick should depend on the unique circumstances of your company and your data team. Are you willing to spend more on cloud software, in lieu of hiring data engineers? Or are your constraints such that you have no choice but to optimise for data and query cost?
This fundamental tradeoff between the two may be difficult, but at least you now know that it exists. It should be an interesting exercise to ask yourself, the next time you look at a data stack: is this company optimising for stack costs or engineering costs? The answer may surprise you.

Staff writer at Holistics. Enjoys Python, coffee, green tea, and cats. I'd love to talk to you about the future of business intelligence!