First Impressions from Agile Data Warehouse Design
Agile Data Warehouse Design is a 2011 attempt at applying the principles of agile to the practice of data modeling. This is the first post in a series on the ideas from the book.

This is a first post in a series on Agile Data Warehouse Design, a 2011 book about data modeling.
I’m currently making my way through Lawrence Corr’s and Jim Stagnitto's Agile Data Warehouse Design, originally published in 2011. To my knowledge, the book was the one of the first major attempts to take the principles of agile and apply them to the practice of Kimball’s dimensional data modeling.
The book’s contributions are interesting. 2011 doesn’t seem like that long ago, but it precedes the creation of Amazon Redshift by a year, and was only a few months after Google BigQuery was first launched. This timeline means that Corr and Stagnitto ’s ideas were developed before the rise of the columnar cloud data warehouse. It also means that many of their ideas no longer transfer as cleanly to the data stacks of today.
The premise of Agile Data Warehouse Design is simple: Corr and Stagnitto noticed that Kimball’s dimensional data modeling depended on a large, up-front exercise at the beginning of every data warehouse project (this is the four-step dimensional modeling design process that we mentioned in this post). Kimball’s approach felt a lot like the ‘waterfall’ model of software development, which was widely considered to be problematic; Corr and Stagnitto’s innovation was to attempt to make the design process more lightweight and iterative, and therefore more ‘agile’.
Did they succeed? I’m about 40% through with the book, but I’m going to go with a ‘yes’ — though I have to say that the authors were limited by the technologies of the time. In fact, like Kimball’s Data Warehouse Toolkit, you may view Agile Data Warehouse Design as two books pretending to be one: on the one hand, it is a collection of design tricks, diagramming techniques, and modeling processes (which the authors named ‘modelstorming’) to be used at the design stage — adapted for the databases and OLAP cubes of the day; on the other hand, the book is a serious attempt to apply the principles of agile to the activity of data modeling. Both books are useful, but the second book is more interesting than the first — and it is the second book that we must focus on if we want to adapt their ideas to the modern data stack.
Let’s talk about what that means.
The Basic Unit of Work
Corr and Stagnitto start with the one of the most fundamental ideas of agile development: that it is better to use smaller, more tightly focused development cycles. Instead of creating a ‘Big Design Up Front’ (or BDUF), the authors argue that it is more prudent to split data modeling efforts into smaller iteration cycles, each cycle involving and satisfying the needs of (different subsets of) stakeholders.
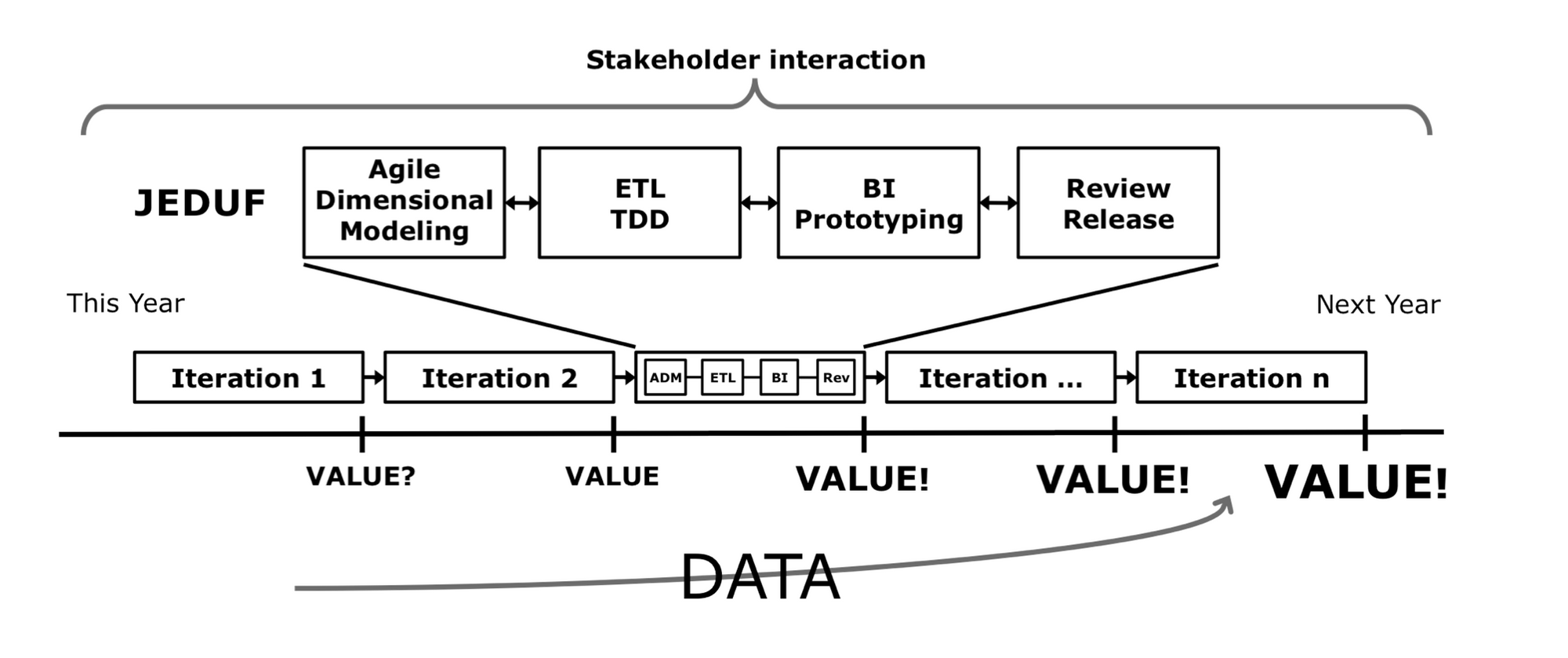
In agile software development, the basic deliverable of each cycle is working software — that is, some set of implemented features that fulfil a customer need. What, then, should be the basic deliverable of each data modeling cycle? Corr and Stagnitto argue:
For agile DW/BI, the working software that adds value is a combination of query- able database schemas, ETL processes and BI reports/dashboards. The minimum set of valuable working software that can be delivered per iteration is a star schema, the ETL processes that populates it and a BI tool or application configured to access it (emphasis added). The minimum amount of design is a star.
The authors then mention that the basic unit of discovery in order to produce a basic unit of work is a business process worth measuring. The first half of the book focuses on techniques to uncover business processes that are stable and immediately measurable, and therefore ‘more resistant’ to report drift. These techniques include intuitive diagramming tricks (for business stakeholders who have little patience for SQL), processes (the primary one named 'BEAM ✲’) and translation techniques to more technical artefacts (for data analysts who prefer DB diagrams).
They then explain that many of their techniques are designed to involve business stakeholders because:
Many of the stakeholders involved in collaborative modeling will become direct users of the finished dimensional data models. Doing some form of dimensional modeling with these future BI users is an opportunity to teach them to think dimensionally about their data and define common, conformed dimensions and facts from the outset.
Collaborative modeling fully engages stakeholders in the design process, making them far more enthusiastic about the resultant data warehouse. It be- comes their data warehouse, they feel invested in the data model and don’t need to be trained to understand what it means. It contains their consensus on data terms because it is designed directly by them: groups of relevant business experts rather than the distillation of many individual report requests interpreted by the IT department.
Never underestimate the affection stakeholders will have for data models that they themselves (help) create.
So far, so intuitive. It becomes clear, then, that much of the book’s value is in providing a repeatable, structured process, while maintaining constant communication with stakeholders.
Would This Work?
I’m not done with the book, but I find many of the people- and process-oriented ideas that Corr and Stagnitto describe rather compelling. That said, the proof of the pudding is in the eating — and the authors naturally describe their approach as the best thing since sliced bread … because of course they would.
To evaluate the ideas from Agile Data Warehouse Design properly would require us to examine those who have put the methodology to practice over the past decade. For instance, in South East Asia, the last major tech company here to have put modelstorming to practice seems to be the people at Indonesian unicorn Gojek; it would do to ask them how their experience has been in the months since. The book’s ideas are also more interesting today because recent technology changes have made it easier to implement most of their ideas.
For instance, the authors argue that an agile data modeling approach must have the following properties:
- To encourage collaboration between stakeholders, agile data modeling needs to be quick. This way, a data department is able to show value, and they won’t wear out their welcome with business stakeholders.
- On the flip side, stakeholders shouldn’t be made to feel that a design is constantly iterating (throwing out past work) when they want to be incrementing (adding functionality to models, to enable new reports).
- Data engineers need to embrace database change. To do this well, Corr and Stagnitto argue that data professionals need tooling that support such changes, including better ETL, data quality tooling, and automated testing.
- Finally, data analysts need to embrace data model change — which also implies tooling to enable the org to keep up with such turnover.
The historical changes that have happened over the past few years (which we’ve covered here, here and here) have made all of these properties easier to achieve.
Over the next few weeks, we’ll be taking a look at the ideas of Agile Data Warehouse Design — but with the modern data landscape in mind. What would Corr and Stagnitto’s ideas look like in an age of Holistics, dbt, and Great Expectations?
Stay tuned to find out.

Staff writer at Holistics. Enjoys Python, coffee, green tea, and cats. I'd love to talk to you about the future of business intelligence!