ETL vs ELT: How ELT is changing the BI landscape

In any organization’s analytics stack, the most intensive step usually lies is data preparation: combining, cleaning, and creating data sets that are ready for executive consumption and decision making. This function is commonly called ETL or Extract, Transform, and Load, identifying the three distinct stages involved. ETL and other data warehousing related concepts evolved in a technology era where the operational technology stack, understanding of risk, and non-functional requirements were much different than they are today.
This article talks about the technology changes that is driving the emergence of ELT, and provides a comparison of ELT vs. ETL to assess your company’s data needs.
For a more up-to-date analysis of ETL vs ELT, check out chapter 02 in our Analytics Guidebook: ETL vs ELT? What Is The Big Deal?
The Origins of ETL
The seminal work in data warehousing and business intelligence were done in an era in which:
- Most OLTP systems were hosted on expensive mainframe systems, or proprietary "enterprise database" technologies (Oracle, Sybase etc.).
- Tables were modeled and persisted to ensure optimal performance of
customer-facing applications, and to reduce the overall storage footprint. - Large enterprises, who were the first beneficiaries of BI, had no tolerance for system downtime, and hence focused on keeping their OLTP systems stable.
Analytical queries, however, tend to be built iteratively, and run across
multiple tables in an OLTP database. These differences between Transactional
Systems and analytics posed a challenge, and led to the need for data to be
processed or queried outside the OLTP systems.
Thus, a new category of software — ETL Tools — was born. These tools:
- Extracted data from OLTP databases into another server, where operational data could be “Transformed” into reporting data sets.
- Different data sets were combined and processed in a dedicated server, and the final data set was Loaded into a target database: the data warehouse.
Benefits:
Now, analysts, business users, and data scientists could interact and query the data without disturbing business operations. More importantly, most ETL tools eliminated the need to code: They provide a drag, drop, click, and configure interface which breaks the transformation steps into distinct “stages”. ETL specialists could build step-wise routines that were easy to trace and debug without the need to understand code written by engineers. This was indeed the core value proposition: one didn’t need to be an engineer or developer to build something of tremendous value to the organization. For example, DataStage provides an array of options for data processing as shown below:
The Cost:
- ETL Software ran on dedicated hardware infrastructure, usually consisting of multiple servers, to provide scalability.
- One long-term impact with the increased sophistication of ETL software was that a class of professionals who became “Certified Developers” in a specific ETL tool started to emerge. Thus, hiring or training talent that could work with software that were becoming increasingly complex eroded the original value of not requiring engineers: the focus simply shifted to another class of specialists. An example is below:
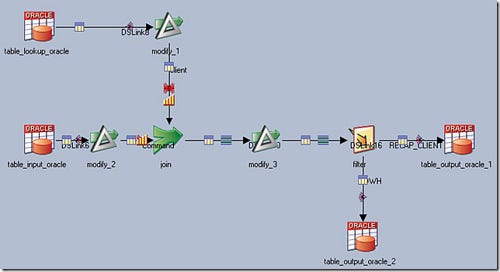
A sample ETL Job in IBM DataStage: This illustrates that no coding is indeed
required, while the end result itself seems complex
Key Changes in the Landscape
There are three changes that occured over the years that have changed the ETL
game:
- Highly-available operational systems started to be powered by RDBMS Technology (lesser use of mainframes)
- Open source database products, such as PostgreSQL, perform comparably well (if not sometimes better)as proprietary RDBMS products, such as Oracle or Sybase, do
- SQL has proliferated as a more commonly available skill compared to traditional coding, and is now part of training programs for engineers, analysts, and even business users in some contexts
These have two effects:
- The cost of ownership of an operational or data warehousing infrastructure have reduced tremendously
- SQL’s simplicity reduced the value of software that “eliminated the need to code”
Thus, instead of having a dedicated ETL Server cluster, companies can now use a database infrastructure for both processing (Data Preparation) and querying
(Data Reporting). Also, instead of investing in a drag-and-drop tool to perform the data transformation functions, companies can now use SQL scripts in conjunction with automation software (or features) for data preparation. While traditional ETL tools can still be extremely powerful in an ELT setup, using SQL as the single currency across your stack offers benefits.
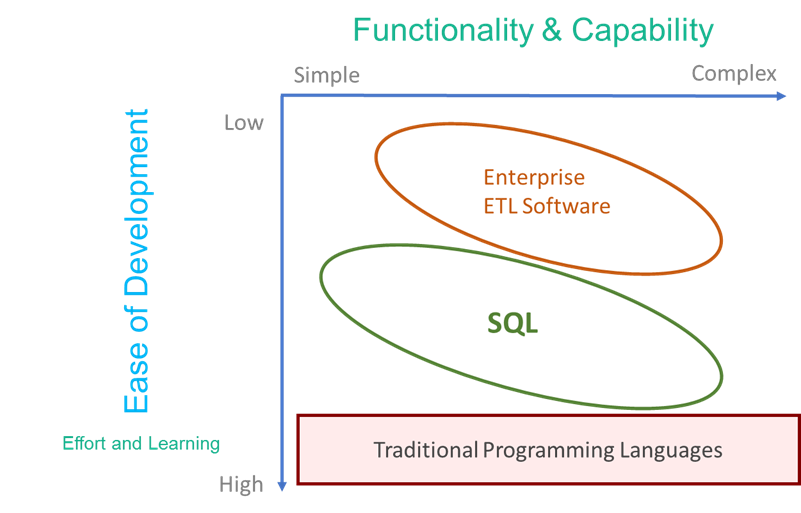
ELT: The logical next-step
The lowest load on an highly-available operational system is reading data or the “Extract” function. Instead of creating an intermediary flat file as older ETL tools do, modern connectors copy data from one database platform to another with a similar workload on the stable OLTP side.
Thus, the flat files have been replaced by tables in the data warehouse schema, thereby “loading” raw data first. Now, we have a copy of the required operational data that can be cleaned (eg. remove Trailing and leading spaces in user input text, correcting errors in address entered), standardized (eg. Resolve all countries into a standard list of 2 character identifier: US, SG, HK etc.), filtered (remove canceled orders etc), masked (obfuscate client-identifying information such as Social Security or National ID numbers), and aggregated (convert and summarize transactions in different currencies into one). Most, if not all, of the steps can be done using SQL queries within the data warehouse environment.
ELT vs. ETL: The Benefits & Considerations
The increased adoption of ELT offers many benefits:
- No dedicated ETL Infrastructure required: Savings in Total Cost of Ownership
- Reduced expense on ELT software:
a. Subscription-based ELT services can replace the traditional and expensive
license + support cost of enterprise software
b. Reduced time-to-market for changes and new initiatives as SQL deployments take much less time than traditional code
c. SQL-savvy analysts can build, maintain, document, and troubleshoot applications easily and more holistically: SQL queries can be seamlessly moved from reporting to preparation - Better utilization of cloud-based databases, as processing steps undertaken during off-hours are not billed as CPU hours
- Flexibility in maintaining copies of operational data (1 month, 6 month, 10 years etc.) for audit purposes, and in storing intermediate processes as tables (Reusability, traceability etc.)
Conclusion
A number of technological changes over the last few years have challenged the traditional notions, not just in Business Intelligence but in other domains as well. Moving to an E-L-T paradigm has cost advantages that are directly measurable, but coupling an elimination of the intermediary ETL tool needs changes to processes and a careful rethink of how analytics is delivered in your organization. Controlling the entire BI / Analytics stack using one language — SQL — is certainly worth considering, as there could be other synergies that could be gained.
About Holistics
Holistics.io provides data collection, preparation, and reporting in one
cloud-based suite, requiring SQL as the only skill to design and own an
end-to-end BI practice. Sign-up for a free 14 day trial at www.holistics.io/getting-started and enter the offer code “ELT”
