What We Know and Don't Know About Analytics Engineering
Everything we know and don't yet know about the emerging role of analytics engineering.


It is 1996. Your boss asks you to set up a business intelligence team. You sit through a bunch of meetings with system integrators, before picking one who promises to deliver your system on time and under budget. They deliver it two years late and a million dollars over budget. Oh well. Your data engineers create and manage data pipelines from your ERP systems, and your data analysts use OLAP cubes to do ad-hoc analyses for businesspeople.
It is 2006. Your boss asks you to set up a business intelligence team. You sit through a couple of vendor meetings, before deciding to go all in on the Tableau ecosystem. You hire a small team of data engineers, who set up and then maintain ETL pipelines from your source systems to your data warehouse. They use Ralph Kimball’s dimensional data modeling to transform that data during the ETL step. It’s a lot of work. Your data analysts then copy slivers of that transformed data and perform their analyses on Tableau software running on their own laptops.
It is 2018. Your boss asks you to set up a business intelligence team. You don’t bother hiring a data engineer. Instead, you set up a sales call with Fivetran, and take out your corporate credit card when they ask you to pay for their software. This allows you to pull data from your other cloud software vendors — software services like Salesforce and Mixpanel and Stripe — which you dump into a cloud-based columnar database. You borrow Steve from product engineering for a few weeks to do this. He sets up dbt. You take dbt and use it transform all that data you have in your data warehouse. You release Steve back to his product team shortly after.
Your data analysts spend their time modeling data, writing tests for said data, and documenting your datasets. They try as much as possible to enable business users to find and manipulate the data for themselves. They’re able to do this because you’ve decided on a tool like Holistics or Metabase or Redash to connect to your cloud data warehouse. Those tools enable easy dashboard and report creation, along with the ability to create and share explorable data marts.
One day, one of your data analysts comes up to you. “You know,” she says. “This is the first analytics job where things feel different. I’m not dealing with data extracts in Tableau. I’m also not talking to data engineers as much, mostly because all of the data I need is dumped into one data warehouse — I just use dbt.”
“That’s great!” you say, “What’s the problem?”
“So I’m spending all this time writing data modeling code, and writing documentation for our data marts and models, and creating dbt tests, and so I don’t spend that much time in raw SQL as much anymore. That worries me.”
“Why does it worry you?”
“Well my friends in banks and other companies are still dealing with SQL and data extracts and Tableau visualizations. Sometimes their bosses tell them to go write some longass query and generate a CSV for a VP to inspect. And I’m not doing any of those things. I’m doing this weird set of activities. What if I become unhireable?”
“Oh,” you say. “Hmm.”
Your data analyst folds her arms and leans against the door to your office. She watches your face carefully.
“I guess —“ you say, thinking back to all the previous systems that you’ve watched over, “Well, I guess … maybe this is the data analyst job of the future.”
And that’s how we got here.
Two years ago, a bunch of people decided to give this role a new name. They noticed that their jobs had changed, and that the set of things that they produced was strikingly different from all the data analyst roles they’d been in in the past.
They decided to call this new job ‘analytics engineer’; as opposed to ‘data analyst’.
Thus, the topic of this blog post.
The Birth of a New Role
The creation of a new role can be incredibly messy. Back in 2010, I distinctively remember jokes about how ‘data scientist’ just meant ‘overglorified statistician’. It took us a while before we collectively understood that ‘data scientist’ meant ‘someone with more software engineering ability than a statistician, and with more statistical knowledge than a software engineer.’
Even today, however, the Wikipedia page on data science sports a line reading “There is still no consensus on the definition of data science, and it is considered by some to be a buzzword.”

We should expect things to be equally messy with analytics engineering.
It’s worth taking a step back to ask: why come up with a new name for a new role? Why not just call it ‘data analyst’ and be done with it? After all, it is simply the shape of the job that has changed; the outcomes are still identical — data analysts and analytics engineers alike exist to provide business managers with the numbers they need for their decisions. Sure, analytics engineers do different things in their jobs when compared to data analysts, but what they do is very much influenced by the tools and technologies that are available to them.
There are three reasons for this. (There are probably more, but these three are mine).
First, because analytics engineers and data analysts do different things, it is useful — from a signalling standpoint — to differentiate between the two kinds of jobs. Companies that use a contemporary data stack are likely to want a different sort of data professional compared to companies that work with data extracts and Tableau. Similarly, analytics engineers who write and maintain data models and data tests would likely want to learn different things compared to data analysts who spend their time arguing with data engineers over their last batch of ETL pipeline requests. A new name allows these professionals to find each other, in what is an already crowded industry.
This is a good thing.
Second, analytics engineering requires a different organizational shape. Notice how there’s less reliance on data engineering with contemporary data stacks. Notice also that analytics engineering work is defined by higher-leverage activities: things like creating reusable data models, documenting and surfacing data resources within the business, or building systems to catch bad data early. This is by design: many of the tools that define today’s data landscape were built in response to the pains of previous generations of data tools; they enable and encourage a higher leverage set of activities.
The implication here is that a data team that consists of analytical engineers will have to be run differently from a team that consists of the typical ‘data analyst, data engineer, and data scientist’ triptych. It is useful to know that this is the case; calling this out under a different name will make it easier to talk about the organizational changes that companies would need to make when hiring for analytics engineers.
For instance, the career path for an analytics engineer is likely to be different to that of a data analyst — since the analytics engineer does higher impact things, and is no longer exclusively a junior role. Second, the nature of analytics engineering means that the hiring practices around a data team must change as well; in the dbt blog post about analytics engineering, for instance, Claire Caroll writes:
It turns out, your company can get pretty far with a single analytics engineer working as a data team of one supporting a whole business. But for those companies that need a larger data team, how does this team structure scale? Do you simply hire another analytics engineers? Or do you diversify?
In our experience, we see team members start to become more specialized, with roles that align more closely with those that we started with. Depending on your needs your next hire may be a data engineer, or a data analyst.
Third and finally, analytics engineering is simply a good excuse for data vendors to reposition themselves. This is good ol’ enterprise marketing, and it is ultimately why so many companies are talking about analytics engineering today (ourselves included!)
The logic is as follows: you are a BI tool vendor, and you want to stand out from the incumbents. What do you do? The answer: you invent a new category, and then you position yourself as one of the first companies to serve that category.
Michael Kaminsky wrote The Analytics Engineer in January of 2019. In October the same year, Claire Carroll of dbt wrote When did analytics engineering become a thing? And why?. Shortly afterwards, dbt repositioned their entire company to become ‘the analytics engineering workflow tool’, a position that has continued till today:

It was perhaps questionable if ‘analytics engineering’ really was a thing in 2019. Sure, the ideas existed in the zeitgeist, but we at Holistics were more familiar with the term ‘dataops’ as a placeholder for these ideas. In 2020, however, the folks at dbt ran Coalesce, a conference on analytics engineering; they also raised 12.9 million dollars to accelerate this trend. The ideas behind ‘dataops’ seemed to have been subsumed into ‘analytics engineering’ in the months since.
dbt’s positioning is ultimately why I think analytics engineering will become a thing: they are absolutely motivated to create the category. This is both good marketing, and — to their credit — a good name for a wave that truly exists.
Now we just have to figure out what it all actually means.
What Exactly is Analytics Engineering?
The honest truth is that we just don’t know.
In his original blog post on The Analytics Engineer, Michael Kaminsky wrote:
While data scientists and analysts are writing a lot of code, being great software engineers isn’t what they’ve been trained for and it often isn’t their first priority. Similarly, while data engineers are great software engineers, they don’t have training in how they data are actually used and so can’t always partner effectively with analysts and data scientists.
I believe this gap should be filled in by analytics engineers. Their job is to:
Write production-quality ELT code with an eye towards performance and maintainability
Coach analysts and data scientists on software engineering best practices (e.g., building testing suites and CI pipelines)
Build software tools that help data scientists and analysts work more efficiently (e.g., writing an internal R or Python tooling package for analysts to use)
Collaborate with data engineers on infrastructure projects (where they advocate for and emphasize the business value of applications)
You can sort of see that Kaminsky is being aspirational here. He believes that analytics engineers should be more software engineering in their orientation; he expects them to write software to help the analyst with their jobs.
In her dbt blog post, on the other hand, Claire Carroll gives us the following table:
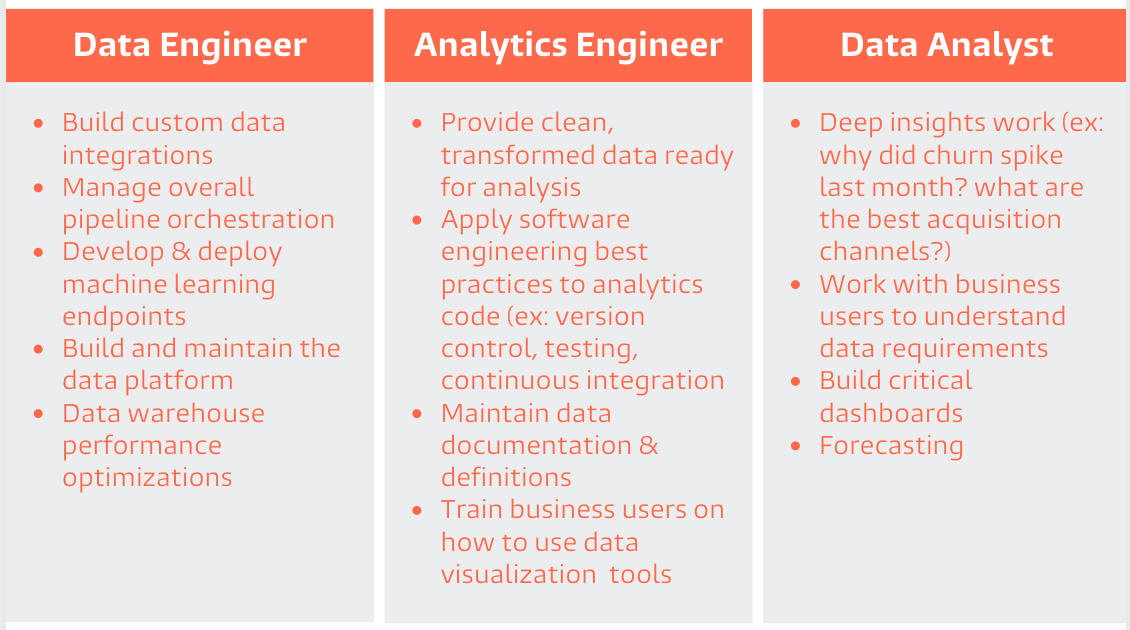
She then writes:
The lines between these roles are blurry – some analytics engineers might spend time doing analyst work like deep dives, while others might be comfortable writing production level Python code but realize doing so often isn’t the highest leverage use of their time.
The term “analytics engineer” is pretty new, and a lot of people doing analytics engineering work don’t go by this title (I didn’t a year ago!). So how do you know if you’re an analytics engineer?
On the surface, you can often spot an analytics engineer by the set of technologies they are using (dbt, Snowflake/BigQuery/Redshift, Stitch/Fivetran). But deeper down, you’ll notice they are fascinated by solving a different class of problems than the other members of the data team. Analytics engineers care about problems like:
Is it possible to build a single table that allows us to answer this entire set of business questions?
What is clearest possible naming convention for tables in our warehouse?
What if I could be notified of a problem in the data before a business user finds a broken chart in Looker?
What do analysts or other business users need to understand about this table to be able to quickly use it?
How can I improve the quality of my data as its produced, rather than cleaning it downstream?
She doesn’t mention writing new software, and that’s perfectly fine — she was writing from the perspective of using dbt as a central tool in an analytics workflow. But the definition had drifted.
Finally, in December last year, Spotify data team members Peter Gilks & Paul Glenn wrote Analytics Engineering at Spotify, where they said:
At Spotify, we’ve spent the last two years initiating, defining and evolving the role of analytics engineer. Peter was not alone in his realizations about the key problems data practitioners at Spotify faced, and when Michael Kaminsky’s blog post on analytics engineering dropped just a few weeks after we’d settled on the same job title for my role, it was a very clear signal that we were on the right track.
Early on, I described the role of an analytics engineer as someone who “reduces the complexity surface data scientists need to engage with in order to create meaningful insights.”
Which is again a slightly different thing.
The best answer I can give, I think, is this: last year, we wrote a short book called The Analytics Setup Guidebook. The book gives you a high level overview of a contemporary analytics stack, and enough history to explain how that stack came to be.
I’d argue that analytics engineering is whatever ends up taking advantage of all the high-leverage, high-impact opportunities afforded by these contemporary tools. We just haven't come to a consensus on what that’s going to look like quite yet.
Perhaps that’s ok. In 2010, data science may have been a thing, but Jupyter Notebooks (then called iPython notebooks) weren’t yet something worth calling home about. It took a few more years before Jupyter came into its own. Today, it’s crazy to imagine data science without some form of interactive notebook, and harder still to imagine a world without the Jupyter ecosystem. But in the same way that it took Fernando Perez ten years to figure out the core architecture of the Jupyter project (with his major breakthrough in 2010); it could well be some years yet before we work out all the full implications of analytics engineering as a career path.
And that’s ok — we live in exciting times, indeed.
What's happening in the BI world?
Join 30k+ people to get insights from BI practitioners around the globe. In your inbox. Every week. Learn more
No spam, ever. We respect your email privacy. Unsubscribe anytime.
