A Dive Into Metadata Hubs
A look into metadata hubs, which might just be the hottest category of data tools of the past two years.

There’s something going on with ‘metadata hubs’ today. In the past two years alone, we’ve seen a whole host of metadata hub projects being released, written about, or open sourced by major tech companies. These include:
- Airbnb’s Dataportal
- Netflix’s Metacat
- Uber’s Databook
- LinkedIn’s Datahub
- Lyft’s Amundsen
- Spotify’s Lexikon
- and Google Cloud Platform’s Data Catalog (though I’m only including this because it seems like a response to the current trend of metadata hubs in the market).
The goal of this blog post is to quickly summarise the problem these products are created to solve, give a quick overview of each of the projects, and then drill down on what seems like the two most promising ones: LinkedIn’s Datahub, and Lyft’s Amundsen.
What is a Metadata Hub?
Imagine that you’re a data user or a data analyst in a large company, with many offices around the globe. Your data organization is spread out across those locations, and you have thousands of tables in different data warehouses and BI tools, plus hundreds of reports, datasets, and data models in varying stages of analysis spread across your entire company. You need to find a report that you need, or a dataset that you want. If you can’t find those things, then you need to find the next best thing: you need to know who to ask, or which team in the organization to direct your query to.
Enter the metadata hub.
The goal of the metadata hub is to act as a ‘search engine’ for the entire data ecosystem within your company. The ‘metadata’ in the name means ‘data about the data’. This includes information like your table schema, your column descriptions, the access records and SLAs associated with each database or data warehouse, and also things like “which team is responsible for this dataset” and “who was the last person to have created a report from it?”
Of course, as Mars Lan of LinkedIn’s DataHub puts it: “if you are able to find out where everything is by asking one person in your company, then you definitely don’t need this.” Metadata hubs only become important when you are a large organization, and you need to scale data access across that entire organization. You’ll hear words like ‘data democratization’ and ‘data discoverability’ being thrown around a lot; what they’re really referring to is the ability for a random data analyst to keep up with the rest of a very large data-producing and data-consuming organization.
Broadly speaking, all of the metadata hub projects I’ve mentioned above provide some combination of the following:
- A search interface for end-users.
- An explorable interface for users to browse and navigate different data sources, and drill down to the table or row level.
- An API service that exposes metadata for other internal data services to consume.
- Some ability to select, save, and curate collections of metadata.
Certain projects, like Airbnb’s Dataportal and Spotify’s Lexikon, are able to expose user profiles, so that you may find individuals or teams who have last touched the dataset you are interested in. But others do not.
The Projects, Briefly
I’m going to go over the projects in chronological order, and give you enough outbound links to go and chase down the original announcement posts, repositories (if available), and tech talks, if you wish. But if you want to get to the good bits, I’d recommend skimming this section (paying special attention to the bits about Amundsen and Datahub) and then skip forward to the next section, where I compare the two projects. Those two seem to have the most community activity around them right now.
Airbnb’s Dataportal, 11 May 2017
The earliest project in this list is Airbnb’s Dataportal. Dataportal was first described on stage by Chris Williams and John Bodley at GraphConnect Europe 2017 (slides available here). They then published a blog post a day later, on May 12th 2017, describing the system.
Dataportal kept track of who produced or consumed data resources within Airbnb. The project modelled these relationships as a graph in neo4j, which then meant that they could provide a search engine, using the Pagerank algorithm, to surface those connections to users.
Dataportal was never open-sourced, and interestingly enough, doesn’t show up on https://airbnb.io/projects/. We haven’t heard about it since.
Netflix’s Metacat, 15 Jun 2018
About a year later, Netflix published a blog post describing their metadata system, named Metacat. This project was built to plug a hole in Netflix’s data stack — essentially, they needed a metadata service to sit between their Pig ETL system and Hive.
The Metacat system lives as a federated service within Netflix’s data infrastructure. It provides a unified API to access metadata of various data stores within Netflix’s internal ecosystem, but it is highly customised to Netflix’s own tools and data stack. It doesn’t seem particularly extensible.
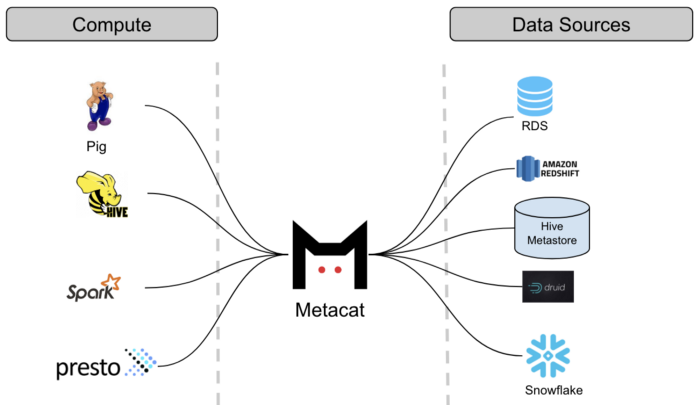
Metacat is open-sourced and actively developed, but not designed for serious external adoption, it seems. As of writing, their Github readme contains a section titled ‘Documentation’ with the words ‘TODO’ written underneath.
Uber’s Databook, 3 Aug 2018
Uber’s Databook was announced in a blog post a month or so after Netflix’s Metacat announcement.
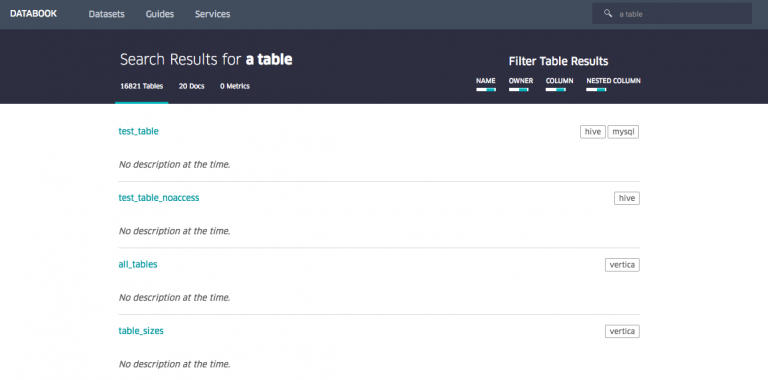
Databook grabs metadata from Hive, Vertica, MySQL, Postgres and Cassandra, and exposes things like table schemas, column descriptions, sample data from the databases, statistics, lineage, freshness, SLA guarantees and data owners, all in one interface. It also allows Databook users to organize and curate these pieces of metadata within their user interface. In the early stages, Databook was built on a crawler architecture (that is, Databook would run crawlers to go out and collect metadata from the various data sources), but as time passed, Uber’s data engineering team eventually switched the system to one built on top of Kafka. They also switched from MySQL to Cassandra in order to support multiple data centres without suffering from increased latency.
Databook is not open sourced, and we haven’t heard about it in the years since. Presumably, it remains widely used within Uber.
Lyft’s Amundsen, 3 Aug 2019
Lyft’s Amundsen was announced on the 3rd of August, 2019, and thenopen sourced a few months later, on the 31st of October the same year.
Amundsen generated some serious buzz when it came out. Tristan Handy of dbt wrote, of Amundsen’s open sourcing:
This product is important, and I really believe the product category is going to be potentially the single most important product category in data in the coming five years. Everything is going to need to feed the catalog.
Amundsen has traces of past systems in its DNA. Like Dataportal, it allows you to search for data resources within your company, and it exposes a discoverable interface down to the row level for each table in each data source it has access to. At launch, the creators also talked about how they intended to integrate with tools like Workday, in order to expose employee information within Amundsen’s search graph, so that you could reach out to fellow employees who had context around the datasets you were interested in.
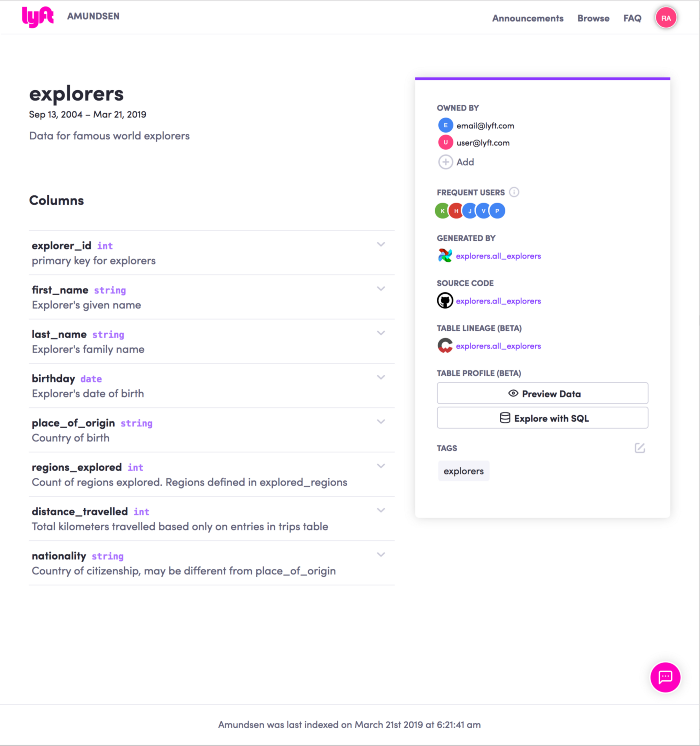
Amundsen consists of a number of different components (source):
- The Metadata Service handles metadata requests from the front-end service as well as other micro services. By default the persistent layer is Neo4j.
- The Search Service is backed by Elasticsearch to handle search requests from the front-end service. This search engine may also be substituted.
- The Front-End Service is a Flask webapp, hosting a React frontend. This is the primary interface that users interact with.
- Databuilder is a generic data ingestion framework that extracts metadata from various sources. It was inspired by Apache Gobblin, and serves as an ETL tool for shoving metadata into Amundsen’s metadata service. It uses Airflow as a workflow tool.
- And finally, Common is a library repo which holds common code among all micro services in Amundsen.
In Amundsen’s launch blog post, the authors note that it has driven down the time to discover a data artefact to 5% of the pre-Amundsen baseline. Amundsen’s community is probably the largest of all the projects covered here, and it is still rapidly growing today.
LinkedIn’s Datahub, 14 Aug 2019
Announced less than two weeks after Amundsen, LinkedIn’s Datahub is actually their second attempt at building a metadata hub. In 2016, LinkedIn open sourced WhereHow, which influenced some of the other projects mentioned in this post. But Datahub was written from scratch to resolve some of the problems LinkedIn experienced with WhereHow.
Most intriguingly, Datahub is built on top of a ‘push-based’ architecture. This means that every data service in one’s organization must be modified to push metadata to Datahub, instead of having Datahub scrape the data from the services. In practice, this is not too difficult to do, since Datahub is built on top of Kafka streams, and Kafka is already widely used within LinkedIn (Kafka was, ahem, created there).
Datahub’s architecture results in a number of interesting benefits. First, it allows incremental ingestion (instead of scraping or snapshotting once every time period). Second, it allows for near-real-time updates, since any change that gets pushed to Datahub will immediately be passed on to downstream consumers. Mars Lan, one of the creators, notes (podcast; around 18:20) that this setup allows you to then build applications that consume the changestream emitted from Datahub, and that they have done this extensively within LinkedIn.
In fact, the entire podcast episode is worth listening to. Lan talks about some of the tradeoffs they needed to make when coming up with an extensible but general data model in Datahub (“you know you’ve succeeded when people spend 90% of their time debating how to model the metadata correctly, and then spend 10% of their time actually coding it.”). It gives you a taste of the depth of experience the engineers brought to the project.
Datahub was open sourced in February this year. More about this in a bit.
Spotify’s Lexikon, 27 Feb 2020 (though built in 2017)
Spotify’s Lexikon covers much of the same ground as previous projects. The original version of Lexikon was built in 2017, in response to an explosion of datasets after Spotify’s move to GCP and BigQuery.
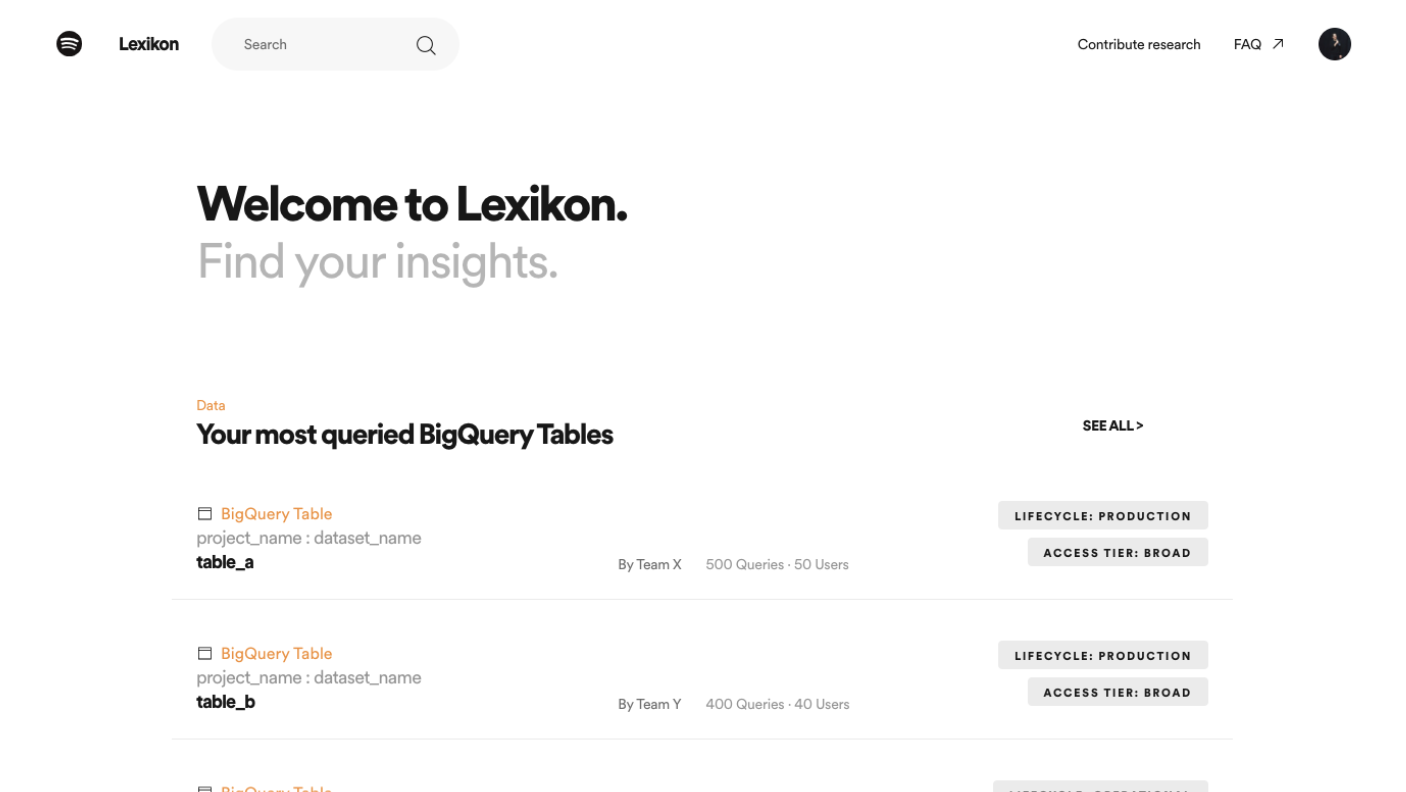
The most novel aspect of the project is that it offers algorithmically generated, personalized suggestions for datasets to data users. (Which is, if you think about it, such a Spotify thing to do). Like Dataportal, Lexikon provides a search experience, and also surfaces users who might help with the dataset you are looking at. Like Amundsen and Datahub, Lexicon shows you table-level and column-level statistics.
Lexikon is not open sourced.
Google Cloud’s Data Catalog, 1 May 2020
Google Cloud’s Data Catalog is a similar metadata service, with the caveat that it only works with GCP services like BigQuery, Pub/Sub, and Cloud Storage filesets. The idea is that you add Data Catalog to an existing GCP-hosted project, flip a switch, and enjoy the benefits of Google’s data catalog by magic.
I’m only including this project for two reasons. First, Google announced that it had reached general availability on the 1st of May 2020, not too long ago. To an outside observer, it seemed like a response to the current flurry of activity in this space, which bodes well for the overall data ecosystem.
Second, Google says that Data Catalog was built on the insights drawn from their Goods data system, which was (is?) used internally at Google as a very effective data catalog service, for many, many years. The paper describing that system may be found here.
Watch Amundsen and Datahub
In this group of projects, Amundsen and Datahub appear to be the frontrunners. Amundsen has a buzzing community, a really snazzy website, and a number of interesting case studies: edmunds.com, ING, and Square. Other companies that have adopted Amundsen include Workday, Asana, and iRobot.
Amundsen has a bit of a head start on Datahub, since it was open sourced in October last year. The community is larger, and as of August 11th, Amundsen is now a Linux Foundation’s AI Foundation Incubation Project. More importantly, you can see project creator Mark Grover’s ambitions in his statement in the press release:
“Becoming a part of the LF AI Foundation is a big milestone for the project in its journey towards becoming the de-facto open-source data discovery and metadata engine. It’s been amazing to see the adoption of Amundsen at Lyft, as well the growth of its open source community, which now has over 750 members. I am excited to see the project’s continued growth and success with the support of the LF AI Foundation.”
On the other hand, Datahub should be taken seriously because of LinkedIn’s track record with open source projects (they created and then open sourced Kafka, which is now a major project in the cloud infrastructure space, and Datahub is built on top of Kafka … making the job of scaling it — in the words of the creators — a ‘solved problem’). According to their Github page, the number of organizations that have adopted Datahub is also pretty impressive: amongst them are companies like Expedia, Saxo Bank, TypeForm, and Experius.
This is notable because DataHub was only open-sourced six months ago. Mars Lan and Pardhu Gunnam was recently interviewed on the Data Engineering Podcast, and they note that the speed of adoption and the growing community has taken them somewhat by surprise. Lan also argued that their approach was superior to everything else on the market, because of hard-won lessons from building WhereHow within LinkedIn more than four years ago (Lan wasn’t involved with WhereHow, it should be noted, but usage of WhereHow has informed the design of Datahub).
Of course, as I’m writing this, it’s been slightly more than a year since these projects were publicly announced, and less than a year since open source adoption started. There’s still a long way to go before they hit maturity.
We live in interesting times, indeed.

Staff writer at Holistics. Enjoys Python, coffee, green tea, and cats. I'd love to talk to you about the future of business intelligence!