The Silos between Data Analysts and Data Engineers

This is part two of the “Silos of Data Organization” series. Part one was sent out last week. For this one, let’s talk about the relationships between the Data Analyst and the Data Engineer in a data org.
I told you guys last time that I was a data engineer in my past life. I have yet to share how I got into the profession: I was a software engineer prior.
Ok, to be more precise, I was graduating from university with a CS degree. But I did two software internships during college (one with a startup in Sweden, and one with Facebook). I’d like to believe those experiences counted too.
At the time (circa 2013), most software jobs in Singapore are web development. When I started looking for jobs, a friend of mine introduced me to a “Data Engineer” job with a local software startup. I took the job simply because the work looks interesting (writing code to process data). I was not that interested in writing code to build web applications.
Why do I tell this story? To make a point: Most data engineers are actually software engineers who happen to write code that processes analytical data.
Look at the data engineers closest to you. Check if this is true:
- They were (or still are) software engineers. Most likely doing platform / backend work.
- Some business requirements happened that require setting up a proper data analytics backend.
- They got pulled into the work because a) There was no one else suitable to work on it and b) They found it interesting and worth giving a shot.
I bet eight out of ten that you will find the pattern above.
Now. Engineers are actually quite a different breed from data analysts.
While Data Analysts care about the business context and meaning of data, Data Engineers (software engineers) usually less so. They care more about building and optimizing the process and system behind producing those numbers.
To them, the numbers don’t mean much because they are not conscious of the surrounding business context. How much is too high? How much is too low? They will defer those to the business and data people. Yes, they think of themselves more of an engineer than a data person.
Data Analysts get a kick out of a brilliant analysis that changes a certain business course. Data Engineers, on the other hand, get a kick out of optimizing something with 40 minutes execution time down to 20 minutes. “A whopping 2x speed improvement”, they say!
So between these two tasks, which one do you think the Data Engineers prefer to work on:
- 1/ Pull in and clean one ad-hoc data table from Accounting system into data warehouse for a special analysis that the Data Analyst is working on for Finance.
- 2/ Migrate storage engine from using CSV to Parquet (a compressed data format) to speed up query performance and reduce storage space.
The obvious answer is (2). I don’t mean to say (2) doesn’t have business outcomes. Just that when it comes to prioritization, Data Engineers have a different sense than the Data Analyst. Selfish you say? Yes, but I think it’s an org dynamics problem, not a personal one.
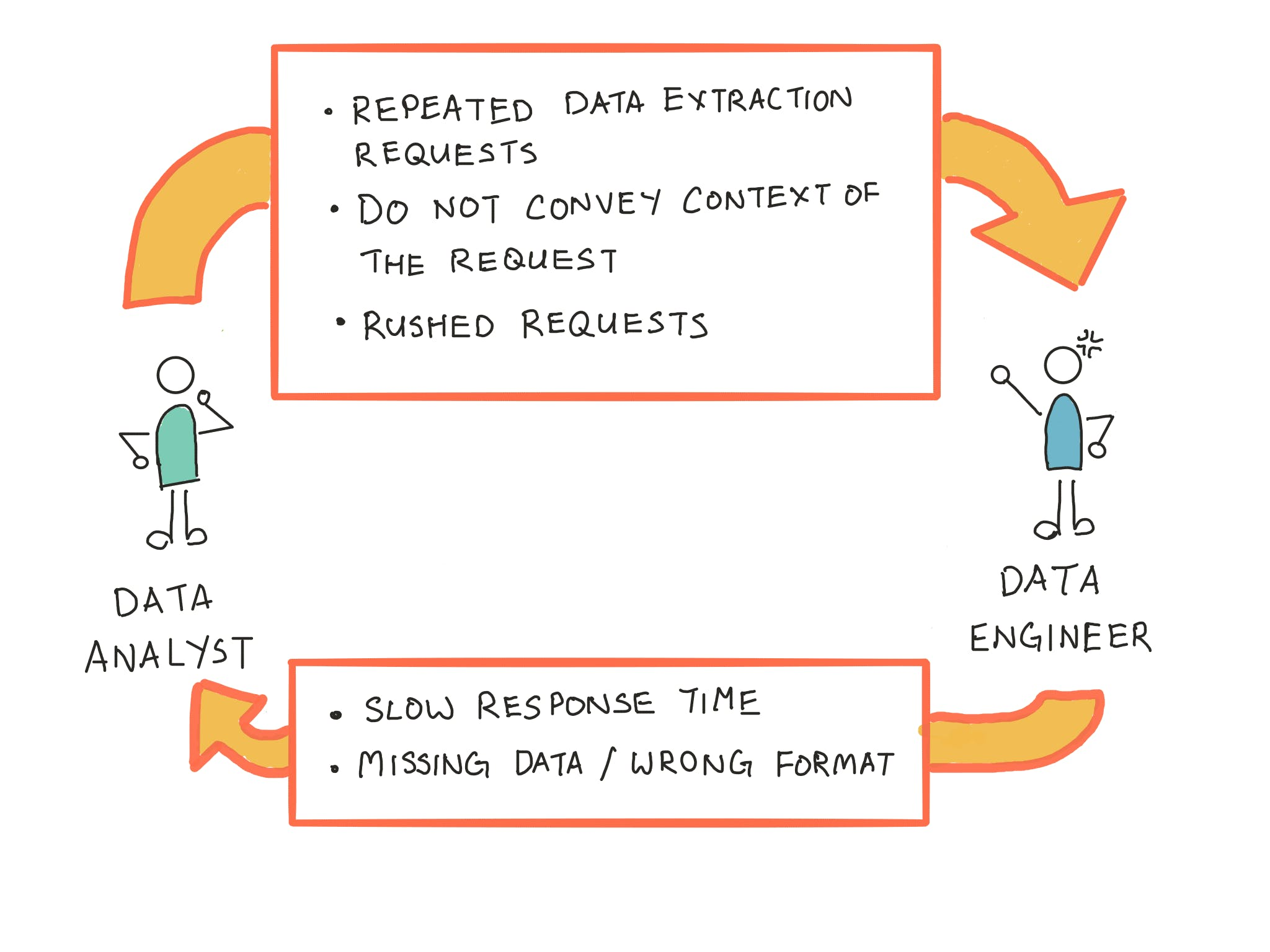
It also doesn’t help that (1) are often times repeated, rushed and meaningless data extraction requests. Ughhh, another boring ad-hoc data extracting requests! Without proper understanding of the business context, there is no motivation for them to maintain pipelines that appear irrelevant to them.
From Data Analysts perspective, it’s frustrating. Under pressure from business users, analysts feel restless when data engineers take too much time to respond to their requests. Analysts cannot understand why what seemingly a simple data pull or transformation can take that long to complete.
Call this silos, frictions, bottlenecks or whatever you will. But this is a real problem between Data Analysts and Data Engineers. And neither one is to be blamed for it.
This problem can be sum up as: “Data Analysts rely on Data Engineers to extract/transform data; But Data Engineers find these work repetitive and boring.”
So. What can we do to resolve this situation?
Fortunately, this one has a simple solution: Provide better tools so that Data Analysts can do the same work Data Engineers do with fewer coding or no coding at all. (*)
In recent years, we are seeing a plethora of data tools entering the market that does exactly this, at different part of the analytics value chain (dbt / Dataform for data transformation, Stitch / Fivetran for Extract & Load; Census / Hightouch for Reverse ETL). This is the underlying premise of the “Modern Data Stack” narrative that has been pushed in the analytics community. When that happens, data engineers won’t need to do these boring, repetitive work anymore.
I will end this post with a gotcha: (*) was not as simple as we thought it is.
BI have been around for 50-60 years. There are plenty of ETL tools prior to Stitch/Fivetran — Pentaho ETL started in 2004, and Talend in 2005, just to name a few.
But ask data analysts and they will tell you how excited they are about the “modern data stack”. It is not the same excitement we get working with data 8-10 years ago.
Something feels different this time. Something that makes the analysts' work smoother, the "analytics logic base" easier to manage, maintain and scale.
I wish to explore this in another post.

Data Engineer turned Product; writes SQL for a living.