3 Points to Consider When Deciding Between Google BigQuery and Amazon Redshift!
What to choose between BigQuerry and Amazon Redshift when it comes to build a cost-efficient, fast, and reliable data warehouse?

As a cloud business intelligence software provider, we often get asked by data analysts, business users and data architects to recommend a cost-efficient, fast, and reliable data warehouse.
Like Pepsi or Coca-Cola, Nike or Adidas, Marvel or DC, corporate rivalries are present in every industry and we love reading about them. In this post, we will be comparing two such rivals - Google BigQuery and Amazon Redshift.
Google BigQuery vs Amazon Redshift Overview
Cloud data warehouses make it easier to work with large sets of data, and provides better query speeds. We will share a brief overview of Google BigQuery and Amazon Redshift below, followed by their comparison.
Google BigQuery
Google BigQuery is an enterprise data warehouse that aims to address the time-consuming and expensive process of storing and querying massive datasets by enabling super-fast SQL queries.
For every query execution Google BigQuery heavily depends on Dremel and Colossus (Google’s file system), and is linked together with Google’s petabit Jupiter network. This system allows every node to communicate with each other at 10Gb/second. Each Google data centre has its personal Colossus cluster, which has enough storage capacity to give every BigQuery user thousands of dedicated disks at a time.
Amazon Redshift
Amazon Redshift is a fast, fully-managed, petabyte-scale data warehouse focused on providing a quick, cost-effective way to analyze data using existing business intelligence tools.
Other databases in the market store data or information by rows, which may require you to read a whole table to sum a column. However, Amazon Redshift system stores each column of a table in block data form, to achieve the goal of reducing the input/output so only relevant data is extracted from disks. The less data you need to read from disk, the faster your query will optimize. By storing each table’s data in chunks called blocks, each of these blocks can be read in parallel. This allows a Redshift cluster to use all of its resources on a single query. When reading from a disk, a Redshift batch can achieve much higher input/output since each node reads from a different disk.
Comparing Google BigQuery and Amazon Redshift
This section describes the key differences between Google BigQuery and Amazon Redshift in terms of speed, ease of maintenance and pricing structure.
1. Speed:
In terms of query execution speed, BigQuery is said to be much faster compared to Redshift. Speed in Redshift is dependent on the size of your cluster and is also limited by the amount of CPU storage you are paying for. With BigQuery, this does not matter, even if you have a large data size for processing it’ll process your query within seconds.
The table below indicates a test done by a group of engineers at Panoply to measure the performance between BigQuery and Amazon Redshift. In terms of loading the data to both Redshift and BigQuery, the table below shows that BigQuery load operations perform slightly quicker. As for querying, BigQuery has exceptional query caching. Redshift caches data and not queries, which enhances Redshift’s performance for similar queries.
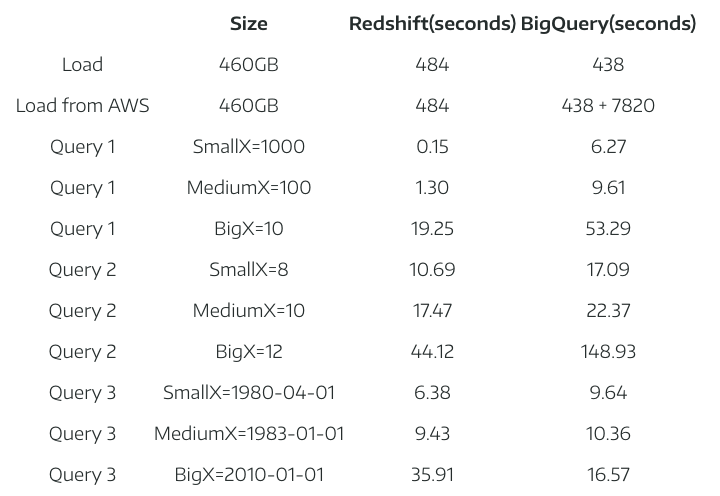
While much research, experiments and comparisons have been done to determine which data source queries faster than the other, it is important to understand the level of complexity for each query and the size of each data table. The speed of querying a database also depends on concurrency or the maximum number of queries that can be run simultaneously in generating interactive reports.
2. Ease of Maintenance:
The two systems have contrasting approaches when it comes to the complexity of optimizing the cluster system. Google BigQuery is a fully self-managed system that does not require the need to resize, vacuum, or adjust distribution.
With BigQuery a data analyst is able to both employ a solution and administrate it - eliminating the need for data specialists. This offers an advantage over Redshift, where maintaining an optimal data warehouse infrastructure requires specialized skills and greater effort to continuously tune the clusters that meet your specific needs.
If you are a data analyst that is looking to spend limited time and resources for more output while using BigQuery, here are a few things that you can do:
- Optimize your queries on the statement level.
- You can easily divide your data over time. If you work with time series data, you can reduce your cost and increase the speed of your query.
- Utilize the exceptional support for nested data structures, avoid flattening out and joining JSON data on your queries.
Amazon Redshift offers a wide range of knobs and pulls that are needed to optimize your cluster. Hence, Amazon Redshift is notably more complex due to the add-on effort required to create a cluster, schedule vacuums, choose sort and distribution keys, and resize your cluster as storage and performance needs change over time. One notable consideration for Amazon Redshift is the need for a skilled worker that understands how to manage the cluster.
If you are inclined towards fine tuning Amazon Redshift performance yourself, here are some important guidelines and tips that you can use:
- Distribution keys - This lets you define how data are distributed across the nodes in your cluster. Generally, you want your data to be evenly scattered across your nodes to utilize all their processing power.
- Sort Keys - As mentioned previously, Redshift is a columnar database, so the way that data is stored in a column matters. Depending on what your queries are, you should use and store the data in sort key order (e.g. timestamp), as pre-sorted data will improve performance considerably.
- Column Compression - Another important factor that may affect your performance is how your data of a specific column is clustered. Here, you try to optimize the size and nature of the data you work with to reduce the time it takes to load the data into memory and work accordingly with it.
Hence, with the points above it is quite evident that BigQuery is far less complicated to control and manage compared to Amazon Redshift. BigQuery is also a serverless service and does not require the need to consider distributing of storage resources around different computers and this carries a huge advantage over Amazon Redshift. With Amazon Redshift, a user must consider the amount of resources required to manage their data warehousing.
3. Pricing Structure:
Google BigQuery and Amazon Redshift are among the most cost-effective solutions available, relative to the other data warehouse solutions in the market. However, the prices between these two solutions are not “neck and neck”, it solely depends on your usage capacity. Hence, it is difficult to compare or predict the cost, because each platform has its own price mechanism and lots of “hidden costs” that will interest you as you start using each solution.
The pricing structure for BigQuery is quite effective. They propose a scalable, adjustable pricing mechanism and charges mainly for data storage and for querying data, but what’s unique is that loading and exporting your data will not cost any money.
BigQuery costs $20/month per TB of data stored, and $5 per TB of data queried. This means that if you have a certain query that requires you to scan a full terabyte of data, that single query will cost you $5. But, you would not have to pay for unused capacity. So, if you are someone who prefers a hands-off approach (while taking into account unpredictable pricing), then BigQuery may be a more suitable data source for you.
Another great feature BigQuery offers is the ability to control and cap your daily cost to an amount that you prefer. It also offers a long-term pricing structure.
Here are some guidelines on how you can save yourself from overspending with BigQuery:
- Arrange the user accessibility within a project by maximizing the number of bytes processed by a given user.
- Try avoiding the SELECT * option on large datasets, instead write down the name of the columns you really need. As BigQuery is columnar, you only pay for the amount of data your query needs to read. Hence, fewer columns selected means fewer columns that need to be read, lowering costs.
- Set a data expiration date on your datasets. After a period of time, all the tables in the datasets will be automatically deleted, so there won’t be any cost incurred on unwanted storage. This is especially useful if you are in the introductory stages with BigQuery.
- If possible, automatically divide your data and store it in sharded tables. If you have selected the right column, usually just that part of the shards will need to be read by a query, which will cut down your costs significantly. This way, you can save more money on the storage side. You can also use the help of the built-in feature by BigQuery that move partitioned data that you haven’t touched in the last “90 days” into cheaper long-term storage.
Amazon Redshift’s pricing structure is mainly based on their cluster configuration system, or the number and type of nodes, and is also based on an hourly rate. Redshift has a higher starting price - the smallest one-node cluster will charge you $180/month, and a standard cluster will probably range from $500 - $1,000/month.
This may make Redshift seem more expensive but there are some advantages that it brings. If you are working for a large corporation, with a standard designated budget to spare, Amazon Redshift may be the perfect solution for you compared to BigQuery, and here’s why:
- BigQuery’s pricing method is unpredictable. You are not able to estimate how much you’ll end up paying by the end of the month. The cost per month may fluctuate depending on your query request.
- BigQuery pricing is a bit more complicated than Redshift. Having to predict how much each query will cost you, and how much you will pay per Gb is extremely difficult as it requires a proper assessment of each query requested and the data it’s going to access.
- This tends to discourage data analysts from querying the database as they end up having to worry about the limit and you’ll need to start controlling the volume of data that is being used.
In terms of simplicity of ease of maintenance, BigQuery comes out on top, but in terms of the level of control you have over your data warehousing setup, Redshift is the winner (for now!). The correct decision really comes down to the mix of skills and resources that you have available in your organization, which is definitely worth thinking about carefully, as a consideration with long term effects.
As important as selecting the right data warehouse, is the next component of finding the right business intelligence (BI) tool or data platform to use. To see how Holistics can help you maximize your data warehouse investment, sign up for a free trial here!

Jatin is a key member of the Holistics family, helping to drive the growth of the company from Jakarta, actively reaching out and getting involved with the data community in Indonesia and beyond.